Wenn es um Backups geht war bacula meist das Mittel der Wahl.
Doch als Bacula kommerziell vermarktet wurde und kaum noch Erweiterungen in die „Community“-Version flossen, beschloss diese das Projekt zu forken. Heraus kam dabei bareos, welches jedoch immer noch voll kompatibel mit bacula ist. Insofern kann (derzeit) die Konfiguration von bacula 1:1 auch für bareos übernommen werden.
Doch bei beiden schreckt die Komplexität viele ab, was völlig unnötig ist: Denn hat man erst einmal die Grundkonzepte verstanden ist bareos ganz einfach und macht richtig Spass!
In diesem Tutorial führe ich zuerst zu einer einfachen bareos Installation und erkläre danach erweiterte Konzepte, welche ganz einfach einzubauen sind.
Die oben erwähnte „Komplexität“ bei bareos kommt hauptsächlich davon, dass bareos auch Bandlaufwerke steuern könnte, was jedoch heutzutage aufgrund der wesentliche günstigeren Festplatten im Vergleich zu Bändern meist nicht gemacht wird.
Ich beschränke mich deshalb in diesem Tutorial nur auf Festplatten als Sicherungsmedium und erkläre auch was dabei beachtet werden sollte.
Demzufolge sind hier mit Sicherungs-Medien immer einzelne Dateien auf einer Festplatte gemeint.
Ich gehe ausserdem davon aus, dass es einen zentralen Backupserver und Clients zum sichern gibt.
Inhalt
Die Komponenten von bareos
Bareos besteht grundsätzlich aus drei Komponenten:
- Director daemon (bareos-dir)
Der director daemon ist die Zentrale Komponente. Er dirigiert den Storage- und den File daemon, so dass diese Sicherungen, Rücksicherungen und Überprüfungen ausführen.
Der director daemon speichert alle Daten zu durchgeführten Sicherungen, zum Beispiel von welchem Client welche Datei auf welches Medium geschrieben wurde.
Darüber hinaus ist der director für die Zeitplanung der Sicherungen zuständig und startet diese selbstständig.
Medienverwaltung und Nachrichtensammlung (log messages) übernimmt ebenfalls der director daemon.
Wichtig zu wissen: Der director speichert seine Informationen in einer Datenbank (mysql oder postgresql), diese wird in bareos catalog (Katalog) genannt. Das heisst, immer wenn vom bareos „catalog“ die Rede ist, ist einfach die Datenbank gemeint.
Darüber hinaus legt der bareos director nach jedem Backup-Job eine sogenannte: Bootstrap-Datei an. In dieser nur wenige KB grosse Datei steht wo und auf welchem Medium die aktuelle Sicherung sich befindet. Diese Dateien sind für einen Notfall gedacht: Denn damit kann man auch bei einem Verlust der bareos Datenbank die einzelnen Sicherungen wieder aus den Medien herauslesen. - Storage daemon (bareos-sd)
Der storage daemon nimmt die zu sichernden Dateien vom Client entgegen und speichert diese auf die Backup Medien. Bei einer Rücksicherung holt er die Daten entsprechend von den Backup-Medien und übergibt sie dem File daemon, damit dieser diese wieder auf sein Filesystem legen kann. - File daemon (bareos-fd)
Der File daemon läuft auf jeden Client der gesichert werden soll. Er liefert während einer Sicherung die vom Director daemon geforderten Dateien an den storage daemon ab oder nimmt diese bei einer Rücksicherung vom storage daemon wieder entgegen und speichert sie auf dem Filesystem des zu sichernden Clients.
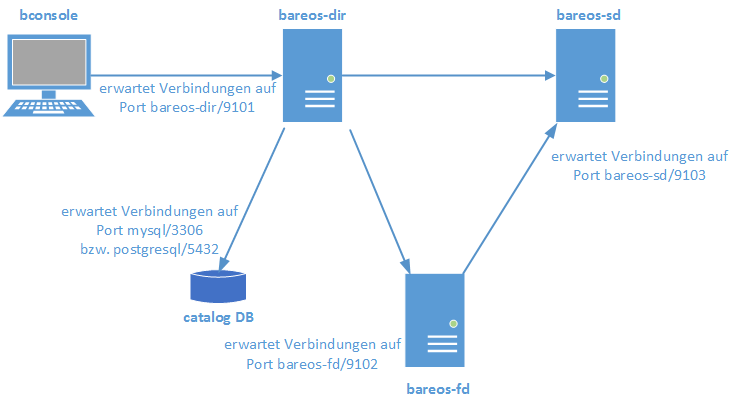
Zum besseren Verständnis, hier ein Beispiel wie so eine Sicherung abläuft:
Auf dem backup Server (bzw. bareos-dir) ist ein Job definiert, welcher auf client-1 das /etc/ Verzeichnis sichern soll.
- Der bareos director verbindet sich mit dem storage daemon und sagt diesem auf welchem Medium er die Sicherung speichern soll.
- Der bareos director teilt dem den File daemon auf client-1 mit, dass er gerne das Verzeichnis: /etc/ haben würde.
- Der file daemon auf client-1 liesst das Verzeichnis /etc/ aus und liefert es direkt beim storage daemon ein.
- Der storage daemon speichert die Dateien auf dem Backup-Medium, welches vom director festgelegt wurde.
Im folgenden ein Diagramm der Verbindungen:
Backup-Konzepte
Bevor es mit der Installation los geht, solltest du dir paar ein Überlegungen über das Sicherungskonzept machen und zwar:
Ausfall des Backupsystems
Fällt bei einem Desaster das Backup System aus, nützen die besten Backups nichts – dann muss nämlich zuerst der ganze backup-server wieder neu aufgesetzt und Konfiguriert werden, was in der bereits schon bestehenden Hektik sehr schlimm sein kann…
Beispiel: Der Backupserver läuft auf einer virtuellen Maschine und der Virtualisierungsserver geht kaputt.
Dann kann man erst mit der Rücksicherung beginnen, wenn man einen neuen Backupserver aufgesetzt hat. Die Konfiguration des Backupservers wurde zwar gesichert, jedoch kommt man da auch nicht ran, so lange das Backupsystem nicht läuft… Das klassische Henne-Ei-Problem! 😉
Aus diesem Grunde ist es sehr wichtig, dass man die folgenden Komponenten an einen externen Ort kopiert (also keine klassische bareos Sicherung!):
- Die bareos Datenbank-Sicherung (bzw. der „Catalog“)
- Das gesamte bareos Konfigurationsverzeichnis (/etc/bareos/)
- Die Bootstrap-Dateien (vor allem die des BackupCatalog-Jobs)
Ebenfalls sollte man für die bareos Datenbank keinen bestehenden Datenbankserver nehmen, da man, sollte dieser mal ausfallen, auch keine Backups- oder Wiederherstellungen machen kann.
Deshalb installiert man am besten einen dedizierten Datenbankserver direkt auf dem Backupserver.
Trennung der Backup-Medien vom Backup-System
Wenn man das obige Szenario noch ein bisschen weiter denkt und etwa als Sicherungs-Medium eine virtuelle Festplatte aus dem Virtualisierungsserver nimmt hat das Katastrophale Folgen: Verliert man nämlich den storage auf dem Virtualisierungsserver, sind auch alle Backups verloren!
Um dies zu verhindern kommen folgende Lösungen in Frage:
- Auf dem Virtualisierungsserver muss ein dedizierter Datastore mit separater Festplatte erstellt werden, welche ausschliesslich für die Backups verwendet wird
- Wenn der Backupserver als VM läuft eine Festplatte direkt anhängen (z.B. per vmware VMDirectPath I/O passthrough) oder via NAS aus dem Netzwerk mounten
- Als Backupserver eine eigene physische Maschine nehmen
- Die Backup-Medien jeweils auf einen anderen (physischen) Server kopieren
So kann der Backupserver problemlos auch als virtuelle Maschine laufen, so lange man darauf schaut, dass die Backups auf einer separaten (dedizierten) Festplatte gespeichert werden.
[stextbox id=“tip“ caption=“Backupserver-VM mit dedizierter Festplatte“]Eine ideale Kombination ist es, wenn man den Backupserver auf einer VM laufen lässt und daran eine Festplatte direkt anhängt (vmware VMDirectPath I/O passthrough). Nun installiert man auf dieser Festplatte direkt auch das Betriebssystem! Der Vorteil daran ist, dass wenn der Virtualisierungsserver defekt ist, kann man die Festplatte einfach in einen anderen Server oder PC einstecken und hat sofort wieder ein funktionierendes Backup-System! 😉
Da vmware derzeit leider noch nicht von VMDirectPath Festplatten booten kann, muss man dazu einen kleinen Trick anwenden: Zusätzlich eine kleine (ca. 500MB) virtuelle Festplatte anlegen und mit dieser bei der Betriebssystem-Installation ein Software-RAID1 für die Boot-Partition (/boot) erstellen. So bootet die VM und im Notfall läuft das System auch auf einem normalen physischen Server.[/stextbox]
Sicherungsarten
Wenn die Grundsatzüberlungen gemacht sind wo die Sicherungen gespeichert werden kann man sich überlegen wie die Backups gesichert werden und wie lange diese zur Verfügung stehen sollen (Vorhaltezeit).
Bareos kennt dabei die drei Sicherungsarten:
- Vollsicherung
Alle zu sichernden Dateien werden vollständig auf das Sicherungsmedium kopiert. - Differentielle Sicherung
Bei der differentiellen Sicherung werden nur die Dateien kopiert, welche sich seit der letzten Vollsicherung geändert haben - Inkrementelle Sicherung
Die inkrementelle Sicherung entspricht technisch gesehen der differentiellen Sicherung, nur dass hier nur die unterscheide zur jeweils letzten inkrementellen Sicherung kopiert werden.
Diese drei Sicherungsarten werden in der Regel miteinander kombiniert, z.B.:
- Jeden Monat eine Vollsicherung
- Jede Woche eine Differentielle Sicherung (welche jeweils die geänderten Dateien seit der letzten Vollsicherung kopiert)
- Jeden Tag eine Inkrementelle Sicherung (welche nur die geänderten Dateien des letzten Tages kopiert)
Nun muss man noch entscheiden, wie lange zurück man auf die Sicherungen zugreifen, bzw. wie lange man diese behalten will.
Eine gebräuchliche Kombination ist:
| Sicherungsart | Interval | Vorhaltezeit |
| Inkrementelle Sicherung | Tag | 1 Woche |
| Differentielle Sicherung | Woche | 1 Monat |
| Vollsicherung | Monat | 1 Jahr |
Somit lässt sich während:
- einem Jahr, den Zustand vom letzten Monat
- einem Monat, den Zustand der letzten Woche
- einer Woche, den Zustand des letzten Tages
wiederherstellen.
[stextbox id=“tip“ caption=“Vorhaltezeit der Vollsicherung“]Die Vorhaltezeit von einem Jahr bedeutet, dass man insgesamt 12 Vollsicherungen aufbewahrt, was ganz schön viel Platz brauchen kann. Deshalb reicht es in den meisten Fällen, die Vorhaltezeit der Vollsicherung auf z.B. 2 Monate zu setzen, anstelle eines Jahres.[/stextbox]
Installation und Konfiguration
Nun geht es zunächst einmal darum die Komponenten zu installieren und zu konfigurieren.
Infrastruktur
Im folgenden werden diese hostnamen als Beispiel verwendet:
| Domain | example.org | Die FQDN domain |
| Backup Server | backup-server | Der zentrale Backup-Server auf dem dem der bareos director, so wie ein storage- und file daemon läuft. |
| Backup Client | client1 | Ein Clientserver, welcher gesichert wird; auf ihm läuft nur ein file daemon. |
| Externer Server | server1 | Ein externer Server; auf diesem werden die bootstraps und bareos Konfiguration gesichert für den Fall, dass der backup-server selbst mal ausfällt. |
Backup-Server
Zur Vorbereitung muss sowohl beim Server, wie auch bei den Clients, das entsprechende bareos-repository hinzugefügt werden:
wget 'http://download.bareos.org/bareos/release/latest/RHEL_7/bareos.repo' -O /etc/yum.repos.d/bareos.repoFangen wir mit dem backup Server an auf dem alle drei bareos Komponenten (director, storage und file) installiert werden:
yum install bareos-director bareos-storage bareos-client bareos-console mariadb-server mariadbZunächst wird die Datenbank MariaDB (mySQL) konfiguriert, welche später benötigt wird:
systemctl enable bareos-dir
systemctl enable bareos-sd
systemctl enable bareos-fd
systemctl enable mariadb
systemctl start mariadb[stextbox id=“note“ caption=“mariadb/mysql Passwörter“]
Die nachfolgenden Schritte gehen davon aus, dass der Datenbankserver und die bareos Datenbank keine Passwörter haben, was standardmässig der Fall ist.
Dies ist ok während der Installation, aber so sicher nicht für den Betrieb geeignet!
Deshalb müssen die Passwörter für den Datenbankserver und die Bareos-Datenbank zuvor in den folgenden Scripten eingetragen werden:
-
- /usr/lib/bareos/scripts/create_bareos_database
(nur wenn das root/admin Passwort schon gesetzt wurde)
-
- /usr/lib/bareos/scripts/make_bareos_tables
(nur wenn das root/admin Passwort schon gesetzt wurde)
- /usr/lib/bareos/scripts/grant_bareos_privileges
[/stextbox]
Bareos liefert bereits Scripte mit, mit denen die Datenbank und die dazugehörigen Tabellen erstellt werden:
Hinweis: Vorher die Passwörter einfügen, siehe oben.
/usr/lib/bareos/scripts/create_bareos_database mysql
/usr/lib/bareos/scripts/make_bareos_tables mysql
/usr/lib/bareos/scripts/grant_bareos_privileges mysqlNun sollte in der Datenbank auch ein Passwort für den root/admin Account gesetzt werden.
Als nächstes brauchen wir ein Verzeichnis auf dem die backups angelegt werden, z.B. /srv/backup/bareos/. Dieses Verzeichnis muss genügend gross für die Backups sein:
mkdir -pv /srv/backup/bareos/Darin werden gleich einige zusatzverzeichnisse erstellt und die Berechtigungen angepasst:
mkdir -pv /srv/backup/bareos/{bootstraps,devices}
mkdir -pv /srv/backup/bareos/devices/offsite
chown -vR bareos:bareos /srv/backup/bareos/
chmod -vR 750 /srv/backup/bareos/| bootstraps | Hier kommen die anfangs erwähnten bootstrap Dateien hin, welche von da einfach auf einen anderen Server kopiert werden können. |
| devices | Ein „device“ ist ein Gerät, auf dem die Backups gesichert werden können; dies kann ein Bandlaufwerk, ein gemounteter NAS-Speicher oder ein Verzeichnis auf einer Festplatte sein. |
| devices/offsite | Sind noch Server an anderen Standorten vorhanden können hier deren Backups ausgelagert werden; so behält man die Daten auch sicher, sollte z.B. der ganze Standort abbrennen (Disaster-Recovery) |
Jetzt gehts an die Konfiguration. Dazu werden im Bareos-Grundverzeichnis /etc/bareos/ gleich noch ein paar Unterverzeichnisse erstellt und die Berechtigungen angepasst:
mkdir -pv /etc/bareos/conf.d/clients/
chown -vR root:bareos /etc/bareos/
find /etc/bareos/ -type d |xargs chmod -v 750
find /etc/bareos/ -type f |xargs chmod -v 640| conf.d/ | Hier kommen die zusätzlichen Konfigurationen des directors hin (filesets, schedules, usw.) um die Grunddatei bareos-dir.conf möglichst schlank und übersichtlich zu halten. |
| conf.d/clients/ | Hier gibt es pro zu sichernden client eine Konfigurationsdatei. |
Nun kann in dieses Verzeichnis gewechselt werden:
cd /etc/bareos/[stextbox id=“tip“ caption=“Passwörter erstellen mit openssl“]
Nachfolgend werden einige Passwörter für die bareos Komponenten benötigt, welche diese zur internen Kommunikation brauchen.
Und für das generieren sicherer Passwörter für die bareos Komponenten eignet sich openssl hervorragend!
Durch den Aufruf von:
openssl rand -base64 33 |
werden zufällige Passwörter generiert.
[/stextbox]
[stextbox id=“note“ caption=“Anmerkung zu den Konfigurations-Direktiven“]
Bevor bareos die Konfigurationen parsed, werden diese alle von den Leerzeichen befreit und in Kleinbuchstaben umgewandelt.
Daher ist es Egal ob man in der Konfiguration z.B.:
Name,
NaMe, oder
Na Me
schreibt.
[/stextbox]
Director
Die bareos director Konfigurationsdatei (bareos-dir.conf) kommt mit Beispielen für einige Szenarien, was die Datei sehr unübersichtlich macht.
Also wird die zunächst geleert und dann neu mit folgendem Inhalt erstellt:
echo > bareos-dir.confbareos-dir.conf
Director
{
Name = bareos-dir
DIRport = 9101
QueryFile = "/etc/bareos/query.sql"
Maximum Concurrent Jobs = 1
Password = "@@DIR_PASSWORD@@"
Messages = Daemon
}
Catalog
{
Name = MysqlCatalog
dbdriver = "mysql"
dbname = "bareos"
dbuser = "bareos"
dbpassword = "@@DB_PASSWORD@@"
dbaddress = "localhost"
}
Messages
{
Name = Standard
mailcommand = "/usr/sbin/bsmtp -h localhost -f \"\(Bareos\) \<bareos@localhost\>\" -s \"Bareos: %t %e of %c %l\" %r"
operatorcommand = "/usr/sbin/bsmtp -h localhost -f \"\(Bareos\) \<bareos@localhost\>\" -s \"Bareos: Intervention needed for %j\" %r"
#mail = root@localhost = all, !skipped
#mail = root@localhost = !all
operator = root@localhost = mount
console = all, !skipped, !saved
append = "/var/log/bareos/bareos.log" = all, !skipped
catalog = all
}
# Message delivery for daemon messages (no job).
Messages
{
Name = Daemon
mailcommand = "/usr/sbin/bsmtp -h localhost -f \"\(Bareos\) \<%r\>\" -s \"Bareos daemon message\" %r"
#mail = root@localhost = all, !skipped
mail = root@localhost = !all
console = all, !skipped, !saved
append = "/var/log/bareos/bareos.log" = all, !skipped
}
# Restricted console used by tray-monitor to get the status of the director
Console
{
Name = bareos-mon
Password = "@@MON_DIR_PASSWORD@@"
CommandACL = status, .status
}
# Include other files
@|"sh -c '/bin/find /etc/bareos/conf.d -type f -name \"*.conf\" -exec echo @{} \\;'"
</bareos@localhost\></bareos@localhost\>Die Sektion kurz erklärt:
| Director | Die Konfiguration des director daemons selber und das Passwort um sich mit diesem zu verbinden. |
| Catalog | Gibt die Katalog-Datenbank an. |
| Messages |
Der erste Messages-Block bestimmt was mit den log Nachrichten während dem backup passiert; ob sie in ein logfile geschrieben (append)-, in die bareos console (console), in die catalog Datenabnk geschrieben (catalog) oder als mail (mail) verschickt werden. Im zweiten Messages-Block geht es nur um die Meldungen des daemons. Wenn der Status von bareos mit einem Monitoring Tool, beispielsweise icinga überwacht wird, können die mail Kommandos auskommentiert werden um nicht doppelt mails zu erhalten. 😉 |
| Console | Der Zugang mittels des CLI Verwaltungstools von bareos (bconsole) |
Die letzte Zeile stellt noch sicher, dass all die Konfigurationsdateien in conf.d/ eingebunden werden.
Nun wird noch das Sicherungsmedium in conf.d/storage.conf definiert. Obwohl dieses meist auf dem selben Server liegt, muss zwingend eine Adresse angegbeen werden, welche die Clients auch erreichen (also nicht „localhost“!).
Dies liegt daran, dass der Client sich direkt mit dem storage-daemon, bzw. der in der Konfiguration angegebenen Adresse verbindet.
conf.d/storage.conf
Storage
{
Name = disk01
Address = backup-server.example.org
SDPort = 9103
Password = "@@SD_PASSWORD@@"
Device = disk01
Media Type = File
}
# Scratch pool definition
Pool
{
Name = Scratch
Pool Type = Backup
}
# default file pool
Pool
{
Name = file01-default
Pool Type = Backup
Recycle = yes
AutoPrune = yes
Volume Retention = 1 day
Volume Use Duration = 23h
Label Format = "default-"
}
# Catalog pool (to seperate catalog backups from "full" backups)
Pool
{
Name = file01-catalog
Pool Type = Backup
Recycle = yes
AutoPrune = yes
Volume Retention = 1 month
Volume Use Duration = 23h
Label Format = "catalog-"
}
# File Pool for full backups
Pool
{
Name = file01-full
Pool Type = Backup
Recycle = yes
AutoPrune = yes
Volume Retention = 2 month
Volume Use Duration = 23h
Label Format = "full-"
}
# File Pool for differential backups
Pool
{
Name = file01-diff
Pool Type = Backup
Recycle = yes
AutoPrune = yes
Volume Retention = 1 month
Volume Use Duration = 23h
Label Format = "diff-"
}
# File Pool for incremental backups
Pool
{
Name = file01-incr
Pool Type = Backup
Recycle = yes
AutoPrune = yes
Volume Retention = 1 week
Volume Use Duration = 23h
Label Format = "incr-"
}
Und wieder das Passwort für @@SD_PASSWORD@@ generieren und setzen.
[stextbox id=“note“ caption=“Anmerkung zu pools“]
Bareos verwendet Dateien („Volumes“) wie Bandlaufwerk-Tapes, d.h. es wird einfach nur sequentiell auf die Datei geschrieben. Ein „herauslöschen“ von (alten) Daten aus diesen „virtuellen Bändern“ ist nicht möglich. Die Datei kann nur komplett überschrieben werden. Wenn man nun also Vollsicherungen ein Jahr-, Inkrementelle Sicherung jedoch nur eine Woche behält und diese auf die gleiche Datei schreibt, wären sie ebenfalls ein ganzes Jahr blockiert. Damit käme eine riesige Datenmenge zusammen von Sicherungen, welche man schon lange nicht mehr braucht.
Daher ist es sehr wichtig für jeden Backup-Typ einen eigenen Pool zu haben.
[/stextbox]
Nun kommt noch der Grund-Zeitplan in conf.d/schedules.conf:
conf.d/schedules.conf
Schedule
{
Name = "WeeklyCycle"
Run = Full 1st sat at 23:05
Run = Differential 2nd-5th sat at 23:05
Run = Incremental mon-fri at 23:05
}
# This schedule does the catalog. It starts after the WeeklyCycle
Schedule
{
Name = "WeeklyCycleAfterBackup"
Run = Full sun-sat at 23:10
}Dies heisst:
- Jeden ersten Samstag im Monat wird eine volle Datensicherung gemacht
- Jeden zweiten bis fünften Samstag im Monat wird eine differentielle Datensicherungen gemacht
- Jeden Montag bis Freitag wird eine inkrementelle Datensicherung gemacht
Am Sonntag gibt es keine Datensicherung, da die volle Datensicherung am ersten Samstag je nach Datenmenge auch länger als 24 Stunden dauern könnte.
Nun müssen noch erste zu sichernden Verzeichnisse und Dateien in conf.d/filesets.conf angeben werden:
conf.d/filesets.conf
# This is the backup of the catalog
FileSet
{
Name = "Catalog"
Include
{
Options
{
signature = MD5
}
File = "/var/spool/bareos/bareos.sql"
}
}
# A small fileset for testing
FileSet
{
Name = "linux-test"
Include
{
Options
{
signature = MD5
}
File = /etc
}
Exclude
{
File = /var/spool/bareos
File = /tmp
File = /proc
File = /tmp
File = /.journal
File = /.fsck
}
}
# All linux system partitons
FileSet
{
Name = linux-system
Include
{
Options
{
signature = MD5
compression = GZIP
One FS = yes
}
File = /
File = /boot
File = /usr
File = /var
File = /home
#File = /tmp
}
}
# Local backups
FileSet
{
Name = "linux-local-backup"
Include
{
Options
{
signature = MD5
OneFS = no
}
File = /var/spool/backup
}
}
# macOS clients
FileSet
{
Name = "macos-userdata"
Include
{
Options
{
signature = MD5
}
File = /Users
File = "/Users/*/Library/Safari/Bookmarks.plist"
}
Exclude
{
File = "/Users/*/.Trash" # Don't backup trash
File = "/Users/*/Downloads" # Don't backup downloads
File = "/Users/*/Movies/" # Don't backup Movies
File = "/Users/*/Music/" # Don't backup Music
File = "/Users/*/Library" # Can get HUGE and mostly not needed
File = "/Users/*/Library/Mobile Documents" # copies of iCloud data
File = "/Users/*/Library/Containers/com.apple.mail/Data/Library/Mail Downloads" # (temporary) email attachments
File = "/Users/*/Library/Safari/LocalStorage" # Browser cache
File = "/Users/*/Music/iTunes/iTunes Media/" # itunes music (not used currently)
File = "/Users/*/Pictures/Photos Library.photoslibrary" # "Photos Library" app (not used currently)
File = "/Users/*/Nextcloud" # Don't backup Nextcloud cache
File = "/Users/*/Virtual Machines*" # Don't backup Virtual Machines
File = "/Users/*/Virtual Machines.localized/" # Don't backup Virtual Machines
}
}
# dummy fileset
FileSet
{
Name = "Empty"
Include
{
}
}Das erste FileSet sichert den Katalog.
Das zweite das /etc/ Verzeichnis.
Das dritte FileSet sichert das lokale System.
Das vierte FileSet wird dazu benötigt, wenn das eiegtnliche Backup auf dem Client erst durch ein RunScript „vorbereitet“ werdenb muss, z.B. bei Datenbank-Sicherungen.
Das fünfte FileSet („Empty“) sichert gar nichts. Es wird später für spezielle Backup Jobs verwendet die nur ein Script ausführen und keine Dateien in bareos Volumes sichern, z.B. bei offsite-backups.
[stextbox id=“warning“ caption=“Vorsicht bei Verzeichnissen“]
Es macht in bareos einen grossen Unterschied ob man für File z.B: /etc oder /etc/ schreibt. Aufgrund der logik von bareos sichert /etc das etc-Verzeichnis, /etc/ hingegen sichert nichts!
Auch ist zu beachten, dass bareos Standardmässig rekursiv sichert, d.h. eine Anagabe wie: File = / würde dazu führen, dass auch sämtliche Netzlaufwerke gesichert werden würden.
Zudem muss man selber aufpassen, dass man keine „doppelten Angaben“ hat, denn bareos überprüft das nicht. Würde man z.B. File = / und File = /home angeben, so würde das /home/ Verzeichnis immer doppelt gesichert!
[/stextbox]
Dies ist eine einfach Grund-Konfiguration. In diser müssen die @@*_PASSWORD@@ Felder noch mit verschiedenen Passwörtern ersetzt werden. Diese werden nur für die Kommunikation unter den verschiedenen Komponenten gebraucht und müssen nie manuell eingeben werden. Daher können diese auch länger sein.
Storage
Nun geht es an die Einrichtung des storage daemons (bareos-sd).
Dazu leeren wir wieder die bareos-sd Datei:
echo > bareos-sd.confund schreiben folgendes hinein:
bareos-sd.conf
Storage {
Name = bareos-sd
SDPort = 9103
Maximum Concurrent Jobs = 20
}
# List Directors who are permitted to contact Storage daemon
Director {
Name = bareos-dir
Password = "@@SD_PASSWORD@@"
}
# Restricted Director, used by tray-monitor to get the status of the storage daemon
Director {
Name = bareos-mon
Password = "@@MON_SD_PASSWORD@@"
Monitor = yes
}
Messages {
Name = Standard
Director = bareos-dir = all
Description = "Send all messages to the Director."
}
# Devices supported by this Storage daemon
# To connect, the Director's bareos-dir.conf must have the
# same Name and MediaType.
Device
{
Name = disk01
Media Type = File
Archive Device = /srv/backup/bareos/pools/file01
LabelMedia = yes;
Random Access = Yes;
AutomaticMount = yes;
RemovableMedia = no;
AlwaysOpen = no;
}| Storage | Die Konfiguration des director daemons selber. |
| Director | Das Passwort um sich mit diesem daemon zu verbinden (entspricht dem, welches in conf.d/storage.conf) angegeben wurde. |
| Device | Hier wird der Ort angeben wo die Backups gespeichert werden; in diesem Fall das Dateisystem. |
Zum Schluss wird noch das Verzeichnis angelegt in dem die Backup Dateien auf der Festplatte gespeichert werden:
mkdir -v /srv/backup/bareos/devices/file01/
chown -v bareos:bareos /srv/backup/bareos/devices/file01/
chmod -v 750 /srv/backup/bareos/devices/file01/File
Nun wird der backup client in bareos-fd konfiguriert; denn der backup-server ist gleichzeitig auch backup client und sichert sich quasi selbst. 😉
Die Datei bareos-fd muss nicht geleert-, sondern nur angepasst werden:
bareos-fd.conf
# List Directors who are permitted to contact this File daemon
Director {
Name = bareos-dir
Password = "@@FD_PASSWORD@@"
}
# Restricted Director, used by tray-monitor to get the status of the file daemon
Director {
Name = bareos-mon
Password = "@@MON_FD_PASSWORD@@"
Monitor = yes
}
# "Global" File daemon configuration specifications
FileDaemon { # this is me
Name = bareos-fd
FDport = 9102 # where we listen for the director
Maximum Concurrent Jobs = 20
Plugin Directory = "/usr/lib64/bareos/plugins"
}
# Send all messages except skipped files back to Director
Messages {
Name = Standard
director = bareos-dir = all, !skipped, !restored
}Die beiden Director-Blöcke geben wiederum das Passwort an, mit welchem sich der Director verbinden kann und entsprechen dem @@DIR_PASSWORD@@ in bacla-dir.conf.
Console
Zu guter letzt wird noch das Verwaltungsprogramm von bareos, bconsole in der Datei bconsole.conf konfiguriert:
bconsole.conf
# Bareos User Agent (or Console) Configuration File
Director {
Name = bareos-dir
DIRport = 9101
address = localhost
Password = "@@DIR_PASSWORD@@"
}Dieses gibt an wo es den director erreichen kann und dessen Passwort. Das Passwort enspricht der Angabe in bareos-dir.conf.
Zusammenspiel der Komponenten
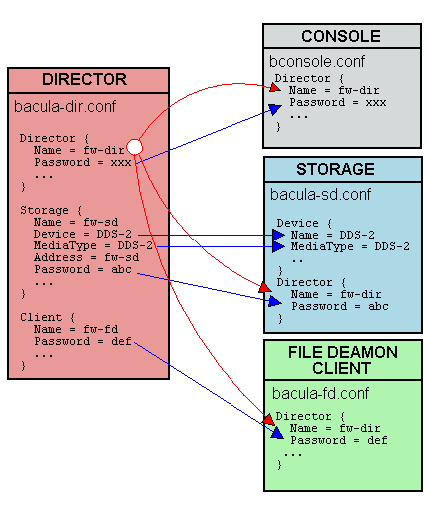
Wie man sieht verbindet sich immer eine Komponente mit der anderen. Der Name des Daemons und das Passwort benutzt dieser um sich bei seinen „Partnern“ zu authentifiziere Zur Übersicht hier eine Grafik wie das abläuft:
Eigensicherung
Zunächst wird noch eine einfache standard Job-Definition in conf.d/ angelegt.
Job-Definitionen sind „Vorlagen“ welche später in den Backup-Jobs angegeben werden können, damit standardmässige Dinge nicht in jedem Job neu geschrieben werden müssen.
conf.d/JobDefs.conf
JobDefs
{
Name = "default"
Type = Backup
Level = Incremental
Schedule = "WeeklyCycle"
Storage = disk01
Messages = Standard
Accurate = yes
Pool = file01-default
Full Backup Pool = file01-full
Differential Backup Pool = file01-diff
Incremental Backup Pool = file01-incr
Priority = 10
Allow Mixed Priority = yes
Write Bootstrap = "/srv/backup/bareos/bootstraps/%n.bsr"
#RunAfterJob = "scp -p /srv/backup/bareos/bootstraps/%n.bsr backup@server1:/srv/backup/bareos/bootstraps/%n.bsr"
}| Name | Gibt den Namen der Vorlage an. |
| Type | Type ist hier immer „Backup“. |
| Level | Level ist in der Regel „Incremental“. Bareos schaut macht daraus selbstständig ein Differentiall- oder Full Backup, je nach Zeitplan. Falls es noch kein Full-Backup gibt, macht bareos immer automatisch Full. |
| Schedule | Hier wird der Zeitplan angegeben, welcher in conf.d/schedules.conf definiert wurde. |
| Storage | Der Sicherungsort, welcher in conf.d/storages.conf dediniert ist. |
| Messages | Wo die log-Einträge zu diesen Backups geschrieben werden; ist normalerweise „Standard“. |
| Accurate | Mit diesem Parameter wird die checksumme der zu sichernden Dateien verglichen, anstatt nur der Zeitstempel; dies braucht zwar etwas mehr Leistung beim sichern, führt aber zu einer akurateren Sciherung und ist für einige erweiterte Funktionen (z.B. „base backups“) auch notwendig. |
| Pool | Die Pool-Definitionen geben an auf welchen Volume-Pool gesichert wird. Die erste Pool Anweisung wird bareos so nie benutzen, muss aber da stehen, da der bareos director immer einen Standard Pool will. Die anderen drei Pool-Anweisungf geben jeweils separate Pools für Full-, Differential-, und Incremental Backups an. |
| Priority | Je tiefer der Wert hier, desto eher wird das Backup gemacht. „10“ ist der Standard Wert. Sicherungen die „vor den anderen“ kommen sollen, können einen tieferen Wert haben und sicherungen welche „zum Schluss“ kommen sollen, einen höheren. |
| Allow Mixed Priority | Damit können Backup Jobs mit unterschiedlichen Prioritäten auch zusammen laufen, wenn in der Warteschlange noch Platz ist. Ansonsten müssen z.B. alle Jobs mit der Priorität 1 immer fertig werden, bevor ein Job mit Priorität 2 beginnen kann. |
| Write Bootstrap | Damit wird angegeben wohin die bootstrap Datei des Jobs gespeichert wird. Den Dateinamen kann man mit diversen Variablen modifzieren; %n ist dabei der Name des Jobs. |
| RunAfterJob | Wenn nach dem Job noch ein Befehl oder Script ausgeführt werden soll. In diesem Beispiel wird die bootstrap Datei nach Beendigung gleich auf einen externen Server kopiert. |
Wie schon erwähnt muss sich der backup-server auch selbst sichern, besonders seine Katalog-Datenbank. Deshalb wird es gleich als ersten client in conf.d/clients/ angelegt:
conf.d/clients/backup-server.conf
Client
{
Name = backup-server
Address = backup-server.example.org
FDPort = 9102
Catalog = MysqlCatalog
Password = "@@FD_PASSWORD@@"
AutoPrune = no
}
# Backup the catalog database (after the nightly save)
Job
{
Name = "ADMIN-BackupCatalog"
JobDefs = "default"
Client = backup-server
Level = Full
FileSet = "Catalog"
Schedule = "WeeklyCycleAfterBackup"
Pool = file01-catalog
Full Backup Pool = file01-catalog
# This creates an ASCII copy of the catalog
# Arguments to make_catalog_backup.pl are:
# make_catalog_backup.pl
RunBeforeJob = "/usr/libexec/bareos/make_catalog_backup.pl MysqlCatalog"
# Copys the file to external server
#RunAfterJob = "scp -pi /srv/backup/bareos/.ssh/id_rsa /var/spool/bareos/bareos.sql backup@server2:/srv/backup/bareos/bareos.sql"
# This deletes the copy of the catalog
RunAfterJob = "/usr/libexec/bareos/delete_catalog_backup"
Priority = 11 # run after main backup
}
# Standard Restore template, to be changed by Console program
# Only one such job is needed for all Jobs/Clients/Storage ...
Job
{
Name = "ADMIN-RestoreFiles"
Type = Restore
Client = backup-server
FileSet = "linux-test"
Storage = disk01
Pool = file01-full
Messages = Standard
Where = /tmp/bareos-restores
}Nun kann alles enabled und gestartet werden:
systemctl enable bareos-dir
systemctl enable bareos-sd
systemctl enable bareos-fd
systemctl start bareos-dir
systemctl start bareos-sd
systemctl start bareos-fd[stextbox id=“note“ caption=“Am Anfang war der Workaround…“]
Startet bareos-dir bei dir nicht und gibt die kryptische Medlung:
bareos-dir: dird.c:1015-0 Could not open Catalog "MysqlCatalog", database "bareos". bareos-dir: dird.c:1020-0 postgresql.c:248 Unable to connect to PostgreSQL server. Database=bareos User=bareos Possible causes: SQL server not running; password incorrect; max_connections exceeded. 08-Mär 16:54 bareos-dir ERROR TERMINATION |
aus? „Häh, postgres fehler, obwohl mysql verwendet wird“? Das liegt daran, dass bareos die standard library des Systems nutzt, was postgres ist.
Um dies zu reparieren reicht ein Aufruf von:
alternatives --config libbaccats.so |
und wählt dort „mysql“ aus.
[/stextbox]
Damit ist bareos nun komplett eingerichtet und Betriebsbereit!
Es sichert bereits täglich seine Datenbank.
Nun können die Backup-Clients hinzugefügt werden.
Monitoring
Damit man sich auf die Backups verlassen kann, sollte der Server und vor allem die Backup-Jobs überwacht werden! – Denn was nützt es, wenn die Sicherungen jedes Mal wegen eines Fehlers fehlschlagen und niemand merkt es?
Dafür gibt es einige Ansätze:
- Einschalten der mail Benachrichtigungen in bareos-dir.conf
- Installieren des Programms bareos-console GUI auf dem Desktop
- Hinzufügen eines automatisches checks zu einem Monitpring-System, beispielsweise icinga/nagios
Letzteres ist mit Abstand die beste Lösung und dafür habe ich ein nützliches check-plugin geschrieben: check_bareos.
Backup-Client
Als erstes wird auf dem Backup Client der bareos file daemon (bareos-fd) installiert:
yum install bareos-clientNun muss noch die Konfiguration in: /etc/bareos/bareos-fd.conf angepasst werden die einzigen Direktiven welche konfiguriert werden müssen sind: @@FD_PASSWORD@@, @@MON_FD_PASSWORD@@ (beide wie bareos-fd.conf auf dem backup-server) und FileDaemon { Name.
Dann noch enablen/starten und schon ist der client bereit um gesichert zu werden! 🙂
systemctl enable bareos-fd
systemctl start bareos-fdSicherung und Rücksicherung
Zurück auf dem backup-server wird der gerade vorbereitete client in conf.d/clients/ eingerichtet:
conf.d/clients/client1.conf
Client
{
Name = client1
Address = client1.example.org
FDPort = 9102
Catalog = MysqlCatalog
Password = "@@FD_PASSWORD@@"
AutoPrune = no
}
# Backup jobs for the client above
Job
{
Name = "client1-testbackup"
Client = client1
JobDefs = "default"
FileSet = "linux-test"
}Nun bareos-dir neustarten.
Die bareos Konsole
Die bareos Konsole (bconsole) ist das Zentrale Verwaltungsprogramm von bareos!
Über diese kann man backups manuell starten, Rücksicherungen auslösen, den Status der Pools, Volumes, Jobs usw. sehen und eigentlich jeden Aspekt von bareos steuern.
Besonders hilfreich ist das auch für die Fehlersuche.
So kann man mittels dem messages Befehl schauen wie der Job läuft, oder ob Fehler auftauchen:
[root@backup-server]# bconsole
Connecting to Director localhost:9101
1000 OK: 1 bareos-dir Version: 7.0.5 (28 July 2014)
Enter a period to cancel a command.
You have messages.
*
*messages
16-Mar 12:40 bareos-dir JobId 37: No prior or suitable Full backup found in catalog. Doing FULL backup.
16-Mar 12:40 bareos-dir JobId 37: BeforeJob: BEGIN copy bareos config
16-Mar 12:40 bareos-dir JobId 37: shell command: run BeforeJob "tar -czf /var/spool/bareos/etc-bareos.tgz /etc/bareos"
16-Mar 12:40 bareos-dir JobId 37: BeforeJob: tar: /etc/bareos/bareos-sd.conf.rpmnew: Cannot open: Permission denied
16-Mar 12:40 bareos-dir JobId 37: Error: Runscript: BeforeJob returned non-zero status=2. ERR=Child exited with code 2
16-Mar 12:40 bareos-dir JobId 37: Error: Bareos bareos-dir 7.0.5 (28Jul14):
Build OS: x86_64-redhat-linux-gnu redhat Enterprise release
JobId: 37
Job: ADMIN-offsite-bareos_config
Backup Level: Full (upgraded from Incremental)
[...]
Termination: *** Backup Error ***Im vorherigen Beispiel war das Problem, dass bareos (genauer das RunScript von bareos) die Datei: /etc/bareos/bareos-sd.conf.rpmnew nicht lesen konnte.
[stextbox id=“note“ caption=“Hinweis“]
Während der normale Sicherungsprozess über den bareos file daemon (bareos-fd) als root läuft, werden die RunScripts, welche vor- oder nach der eigentlichen Sicherung laufen nicht als root sondern als user bareos ausgeführt.
[/stextbox]
Die erste Sicherung
Die Sicherung kann in der bareos Konsole (bconole) mit dem Befehl run manuell gestartet werden:
bconsole
Connecting to Director localhost:9101
1000 OK: bareos-dir Version: 5.2.13 (19 February 2013)
Enter a period to cancel a command.
*run
Automatically selected Catalog: MysqlCatalog
Using Catalog "MysqlCatalog"
A job name must be specified.
The defined Job resources are:
1: ADMIN-BackupCatalog
2: ADMIN-RestoreFiles
3: client1-testbackup
Select Job resource (1-3): 3
Run Backup job
JobName: client1-testbackup
Level: Incremental
Client: client1
FileSet: linux-test
Pool: file01-default (From Job resource)
Storage: disk01 (From Job resource)
When: 2017-03-09 12:44:50
Priority: 10
OK to run? (yes/mod/no): yes
Job queued. JobId=1Gleich danach kommt die Meldung:
You have messages.Durch die Eingabe von messages sieht man dann den Verlauf der Sicherung:
*messages
09-Mar 12:44 bareos-dir JobId 1: No prior Full backup Job record found.
09-Mar 12:44 bareos-dir JobId 1: No prior or suitable Full backup found in catalog. Doing FULL backup.
09-Mar 12:44 bareos-dir JobId 1: Start Backup JobId 1, Job=client1-testbackup.2017-03-09_12.44.53_09
09-Mar 12:44 bareos-dir JobId 1: Created new Volume "full-0001" in catalog.
09-Mar 12:44 bareos-dir JobId 1: Using Device "disk01" to write.
09-Mar 12:44 bareos-dir JobId 1: Bareos bareos-dir 5.2.13 (19Jan13):
Build OS: x86_64-redhat-linux-gnu redhat (Core)
JobId: 1
Job: client1-testbackup.2017-03-09_12.44.53_09
Backup Level: Full (upgraded from Incremental)
Client: "client1" 5.2.13 (19Jan13) x86_64-redhat-linux-gnu,redhat,(Core)
FileSet: "linux-test" 2017-03-08 17:35:47
Pool: "file01-full" (From Job FullPool override)
Catalog: "MysqlCatalog" (From Client resource)
Storage: "disk01" (From Job resource)
Scheduled time: 09-Mar-2017 12:44:50
Start time: 09-Mar-2017 12:44:55
End time: 09-Mar-2017 12:44:56
Elapsed time: 1 sec
Priority: 10
FD Files Written: 1,110
SD Files Written: 1,110
FD Bytes Written: 20,424,014 (20.42 MB)
SD Bytes Written: 20,556,885 (20.55 MB)
Rate: 20424.0 KB/s
Software Compression: None
VSS: no
Encryption: no
Accurate: yes
Volume name(s): full-0001
Volume Session Id: 4
Volume Session Time: 1489058960
Last Volume Bytes: 20,604,995 (20.60 MB)
Non-fatal FD errors: 0
SD Errors: 0
FD termination status: OK
SD termination status: OK
Termination: Backup OKDie erste Rücksicherung
Um nun die Datei /etc/passwd aus dem Backup wiederherzustellen benutzt man den Befehl:restore -> (5) "Select the most recent backup for a client" -> (2) "client1"
in der Bareos-Konsole:
bconsole
Connecting to Director localhost:9101
1000 OK: bareos-dir Version: 5.2.13 (19 February 2013)
Enter a period to cancel a command.
*restore
Automatically selected Catalog: MysqlCatalog
Using Catalog "MysqlCatalog"
First you select one or more JobIds that contain files
to be restored. You will be presented several methods
of specifying the JobIds. Then you will be allowed to
select which files from those JobIds are to be restored.
To select the JobIds, you have the following choices:
1: List last 20 Jobs run
2: List Jobs where a given File is saved
3: Enter list of comma separated JobIds to select
4: Enter SQL list command
5: Select the most recent backup for a client
6: Select backup for a client before a specified time
7: Enter a list of files to restore
8: Enter a list of files to restore before a specified time
9: Find the JobIds of the most recent backup for a client
10: Find the JobIds for a backup for a client before a specified time
11: Enter a list of directories to restore for found JobIds
12: Select full restore to a specified Job date
13: Cancel
Select item: (1-13): 5
Defined Clients:
1: backup-server
2: client1
Select the Client (1-2): 2
Automatically selected FileSet: linux-test
+-------+-------+----------+------------+---------------------+------------+
| JobId | Level | JobFiles | JobBytes | StartTime | VolumeName |
+-------+-------+----------+------------+---------------------+------------+
| 16 | F | 1,110 | 20,424,014 | 2017-03-09 12:44:55 | full-0001 |
+-------+-------+----------+------------+---------------------+------------+
You have selected the following JobId: 16
Building directory tree for JobId(s) 16 ... +++++++++++++++++++++++++++++++++++++++++++
990 files inserted into the tree.
You are now entering file selection mode where you add (mark) and
remove (unmark) files to be restored. No files are initially added, unless
you used the "all" keyword on the command line.
Enter "done" to leave this mode.
cwd is: /
$ cd etc
cwd is: /etc/
$ mark passwd
1 file marked.
$ done
Bootstrap records written to /var/spool/bareos/bareos-dir.restore.1.bsr
The job will require the following
Volume(s) Storage(s) SD Device(s)
===========================================================================
full-0001 disk01 disk01
Volumes marked with "*" are online.
1 file selected to be restored.
Run Restore job
JobName: ADMIN-RestoreFiles
Bootstrap: /var/spool/bareos/bareos-dir.restore.1.bsr
Where: /tmp/bareos-restores
Replace: always
FileSet: linux-test
Backup Client: client1
Restore Client: client1
Storage: disk01
When: 2017-03-09 14:55:18
Catalog: MysqlCatalog
Priority: 10
Plugin Options: *None*
OK to run? (yes/mod/no): yes
Job queued. JobId=19
*
You have messages.
*
*messages
09-Mar 14:55 bareos-dir JobId 19: Start Restore Job ADMIN-RestoreFiles.2017-03-09_14.55.20_07
09-Mar 14:55 bareos-dir JobId 19: Using Device "disk01" to read.
09-Mar 14:55 bareos-dir JobId 19: Bareos bareos-dir 5.2.13 (19Jan13):
Build OS: x86_64-redhat-linux-gnu redhat (Core)
JobId: 19
Job: ADMIN-RestoreFiles.2017-03-09_14.55.20_07
Restore Client: client1
Start time: 09-Mar-2017 14:55:22
End time: 09-Mar-2017 14:55:22
Files Expected: 1
Files Restored: 1
Bytes Restored: 1,029
Rate: 0.0 KB/s
FD Errors: 0
FD termination status: OK
SD termination status: OK
Termination: Restore OKSichern der bareos Infrastruktur
Wie anfangs erwähnt kann es sehr hilfreich sein, wenn man infolge eines Desasters auch die Backup-Infrastruktur schnell wiederherstellen kann!
Deshalb wird noch schnell je ein Job eingerichtet, welcher das /etc/bareos/ Verzeichnis-, so wie die bootstrap Datei des Kataloges auf einen externen Server sichert:
conf.d/clients/backup-server.conf
# [...]
# Backup the bareos configuration of this host
Job
{
Name = "ADMIN-offsite-bareos_config"
Client = backup-server
FileSet = "Empty"
Type = Backup
Level = Incremental
Schedule = "WeeklyCycle"
Storage = disk01
Messages = Standard
Accurate = yes
Pool = file01-default
Full Backup Pool = file01-full
Differential Backup Pool = file01-diff
Incremental Backup Pool = file01-incr
Priority = 10
Allow Mixed Priority = yes
RunScript
{
runswhen = before
RunsOnClient = no
command = "echo BEGIN copy bareos config"
command = "tar -czf /var/spool/bareos/etc-bareos.tgz /etc/bareos"
command = "scp -pi /srv/backup/bareos/.ssh/id_rsa /var/spool/bareos/etc-bareos.tgz backup@server1:/srv/backup/bareos/etc-bareos.tgz"
command = "rm -f /var/spool/bareos/etc-bareos.tgz"
command = "scp -pi /srv/backup/bareos/.ssh/id_rsa /srv/backup/bareos/bootstraps/ADMIN-BackupCatalog.bsr backup@server1:/srv/backup/bareos/ADMIN-BackupCatalog.bsr"
command = "echo END copy bareos config"
}
}Ebenfalls ist es ratsam den „rohen“ dump der bareos Datenbank auf einen externen host weg zu sichern; dazu beim weiter oben definierten Job: ADMIN-BackupCatalog, die Zeile:
RunAfterJob = "scp -pi /srv/backup/bareos/.ssh/id_rsa /var/spool/bareos/bareos.sql backup@server1:/srv/backup/bareos/bareos.sql"auskommentieren.
In diesen zwei Beispielen meldet sich der backup-server mit seinem SSH private key bei backup@server1 ohne Passwort an.
Damit hat man nun eine Produktionsreife Grund-Infrastruktur und kann weitere clients hinzufügen und weitere Konfigurationsmöglichkeiten aus der bareos Dokumentation ausprobieren.
RunScripts
Zeitweise kommt es vor, dass vor- oder nach einer Sicherung noch ein Script oder Programm laufen soll, um beispielsweise ein Datenbank-Dump zu erstellen (vor dem Backup) und dieses danach wieder zu löschen (nach dem Backup).
Dazu gibt es in bareos die RunScripts Anweisung, welche innerhalb eines Job-Blocks definiert wird:
Job
{
[...]
RunScript
{
RunsWhen = "before"
RunsOnClient = "No"
command = "/usr/local/bin/myScript.sh Parameter1"
}
}| RunsWhen | Gibt an ob das Kommando vor (before) oder nach (after) der Sicherung ausgeführt werden soll. |
| RunsOnClient | Standardmässig wird das Kommando auf dem Client ausgeführt („Yes“). Möchte man es stattdessen auf dem Server ausführen kann man den Wert auf: „No“ setzen. |
| command | Gibt das Kommando oder Script an, welches ausgeführt wird. |
[stextbox id=“note“ caption=“Hinweis“]
Dateien die auf diese Weise vorbereitet werden, damit bareos diese „abholen“ kann, sollten per FHS-Standard im Verzeichnis /var/spool/* abgelegt werden. Beispielsweise: /var/spool/bareos/ oder generischer: /var/spool/backup/
Diese Dateien sollten nach der Sicherung durch bareos mit einem RunScript auch wieder entfernt werden.
[/stextbox]
Erweiterte Anwendungen für Backups
Nachfolgend werden noch einige spezielle Anwendungsfälle beschrieben.
Alle lokalen (Linux) Dateisysteme sichern
Um die Gefahr zu verhindern, dass man im FileSet ein Dateisystem vergisst, gibt es einen „Trick“ um automatisch alle lokalen Dateisysteme zu sichern.
Denn in bareos kann man anstelle von Pfaden auch Dateisystem-Typen zum sichern angeben:
# All linux local partitons
FileSet
{
Name = "linux-local-full"
Include
{
Options
{
signature = MD5
compression = GZIP
OneFS = no
FS Type = ext2
FS Type = ext3
FS Type = ext4
FS Type = reiserfs
FS Type = xfs
FS Type = jfs
FS Type = rootfs
}
File = /
}
}Damit werden alle gebräuchlichen Linux-Dateisysteme rekursiv (Da OneFS=no) gesichert, jedoch keine Netzwerk-Freigaben (da diese als Dateisystem jeweils smbfs oder nfs haben).
cross-site
Wenn man zwei Standorte hat, möchte man oftmals die Backups von Standort 1 auf Standort 2 transferieren und umgekehrt. Damit kann sichergestellt werden, dass selbst wenn der komplete Standort verloren geht (z.B. durch einen Brand, Erdbeben, oder andere Naturkatastrophen) die Backups noch immer am anderen Standort vorhanden sind.
Dies nennt man ein sog. cross-site Backup, oder auch „Backup übers Kreuz“.
Bareos hat zwar keinen einegbauten Mechanismus dafür, man kann aber ein „leeres“ Backup (ohne Dateien) erzeugen und in diesem per Pre/Post- Script mittels rsync die Volumes von Standort 1 nach Standort 2 transferieren.
Zunächst installiert man am anderen Standort einen zweiten backup-server wie zu beginn beschrieben; dort lässt man jedoch den director weg, installiert also nur bareos-sd und bareos-fd.
Die Clients/Server am zweiten Standort speichern dann ihre backups dort.
Auf dem Haupt-Backup Server wird dann in conf.d/storage.conf diesen hinzugefügt und ebenfalls noch die pools auf dem zweiten Backup Server definiert. Zusätzlich kann man noch einen extra (pseudo) Pool für den offiste-transfer der Volumes vom zweiten Standort anlegen:
# Storage on second site
Storage
{
Name = site2-disk01
Address = backup-server2.site2.example.org
SDPort = 9103
Password = "@@SD_PASSWORD@@"
Device = site2-disk01
Media Type = File
}
# "Pseudo" storage for offsite backups
Storage
{
Name = site1-offsite01
Address = backup-server.example.org
SDPort = 9103
Password = "@@SD_PASSWORD@@"
Device = site1-offsite01
Media Type = File
}
# File pools for backups on second site
# default
Pool
{
Name = site2-file01-default
Pool Type = Backup
Recycle = yes
AutoPrune = yes
Volume Retention = 1 day
Volume Use Duration = 23h
Label Format = "default-"
}
# full backups
Pool
{
Name = site2-file01-full
Pool Type = Backup
Recycle = yes
AutoPrune = yes
Volume Retention = 2 month
Volume Use Duration = 23h
Label Format = "full-"
}
# differential backups
Pool
{
Name = site2-file01-diff
Pool Type = Backup
Recycle = yes
AutoPrune = yes
Volume Retention = 1 month
Volume Use Duration = 23h
Label Format = "diff-"
}
# incremental backups
Pool
{
Name = site2-file01-incr
Pool Type = Backup
Recycle = yes
AutoPrune = yes
Volume Retention = 1 week
Volume Use Duration = 23h
Label Format = "incr-"
}[stextbox id=“warning“ caption=“Achtung: Pool-Namen müssen bei mehreren Standorten unterschiedlich sein!“]
Bei mehreren Standorten (sites) müssen die pool-namen zwingend anders sein auf jeder site!
Das volume label kann dabei gleich sein.
Der Grund ist, dass bareos nicht automatisch sieht auf welchem device die volumes von einem Pool sind. Daher versucht es dann abwechselnd die volumes von site1 und site2 zu öffnen/beschreiben, was immer dann fehlschlägt wenn der Storage gerade auf der anderen site liegt. Bareos legt dann immer wieder ein neues Volume im aktuellen storage an und markiert das aktuelle als „Fehlerhaft“. Das backup hingegen läuft auf dem neuen volume dannn Fehlerfrei, so dass dies unter Umständen einige Zeit nicht bemerkt wird.
Die Folge davon ist, dass man dann irgendwann hunderte Volumes im Status „Error“ hat. Diese werden nicht mehr verwendet, belegen jedoch weiterhin Speicherplatz.
Im Bareos Logfile bemerkt man dann Einträge wie diesen, wenn der Fehler auftrit: 02-Jan 23:05 bareos-sd JobId 1071: Warning: mount.c:212 Open of file device "site1-disk01" (/srv/backup/bareos/pools/file01) Volume "Incr-0707" failed: ERR=file_dev.c:172 Could not open(/srv/backup/bareos/pools/file01/Incr-0707,OPEN_READ_WRITE,0640): ERR=No such file or directory 02-Jan 23:05 bareos-sd JobId 1079: Warning: mount.c:212 Open of file device "site2-disk01" (/srv/backup/bareos/pools/file01) Volume "Incr-0708" failed: ERR=file_dev.c:172 Could not open(/srv/backup/bareos/pools/file01/Incr-0708,OPEN_READ_WRITE,0640): ERR=No such file or directory |
In diesem Fall hiess der Pool auf beiden Seiten: „file01“.
[/stextbox]
Nun wird in conf.d/JobDefs.conf noch eine Standard-Definition für Backups am zweiten Standort definiert:
JobDefs
{
Name = "site2-default"
Type = Backup
Level = Incremental
Schedule = "WeeklyCycle"
Storage = site2-disk01
Messages = Standard
Accurate = yes
Pool = site2-file01-default
Full Backup Pool = site2-file01-full
Differential Backup Pool = site2-file01-diff
Incremental Backup Pool = site2-file01-incr
Priority = 10
Allow Mixed Priority = yes
Write Bootstrap = "/srv/backup/bareos/bootstraps/%n.bsr"
#RunAfterJob = "scp -p /srv/backup/bareos/bootstraps/%n.bsr backup@server2:/srv/backup/bareos/bootstraps/%n.bsr"
}Und anschliessend werden die zu sichernden Clients/Server noch in conf.d/clients/ erfasst, z.B.
conf.d/clients/site2.client1.conf
Client
{
Name = site2-client1
Address = client1.site2.example.org
FDPort = 9102
Catalog = MysqlCatalog
Password = "@@FD_PASSWORD@@"
AutoPrune = no
}
# Backup the local system
Job
{
Name = "site2-client1-system"
Client = "site2-client1"
Accurate = "yes"
JobDefs = "site2-default"
FileSet = "linux-system"
}Für den Backup Server am Hauptstandort wird nun ein neuer Backup-Job hinzugefügt:
conf.d/clients/backup-server.conf
# ...
# Transfer volumes to offsite locations
Job
{
Name = "offsite-site2_to_site1"
Client = "backup-server"
JobDefs = "site1-offsite"
FileSet = "Empty"
Priority = 15
RunScript
{
RunsWhen = "before"
RunsOnClient = "No"
command = "echo BEGIN offsite transfer site2->site1"
command = "rsync -a --numeric-ids -e 'ssh -i /srv/backup/bareos/.ssh/id_rsa' bareos@backup-server2.site2.example.org:/srv/backup/bareos/devices/ /srv/backup/bareos/devices/offsite/site2-disk01/"
command = "echo END offsite transfer site2->site1"
}
}Beim FileSet wird hier das „Emtpy“ FileSet angegeben, welches nichts speichert.
Dann wird ein RunScript definiert, welches die Dateien vom backup-server2 auf den backup-server am Haupstandort kopiert. – Der Zugriff via rsync muss dabei vom backup-server auf backup-server2 ohne Passwort möglich sein.
Damit hat man die „virtuellen Backupbänder“ vom Standort 2 am Hauptstandort. Und sollte der Transfer fehlschlagen wird auch der Job ferhlschlagen, so dass der administraor darüber gleich automatisch benachrichtigt wird.
Das selbe kann natürlich auch in umgekehrter Reihenfolge für den Standort 1 gemacht werden.
base-backup
Mittels „base backups“ lässt sich in bareos eine Deduplizierung realisieren.
Denn normalerweise werden viele Daten mehrfach gespeichert: Wenn man beispielsweise die Systempartioneen von 10 Clients/Servern mit dem gleichen Betriebssystem sichert, sind bei allen Systemen viele Systemdateien identisch, werden aber ohne spezielle Konfiguration von bareos jedes mal mitgesichert.
Mittels einem base-backup kann man in bareos ein „Grundbackup“ anlegen und dann bei den anderen Jobs auf dieses verweisen. Damit werden dann nur die Dateien gesichert welche nicht identisch zu den Dateien im Grundbackup sind.
Es sollte dabei jeweils ein base-backup pro identischem Betriebssystem und Version (z.B. Centos 7, Windows 10, usw.) angelegt werden.
Hier ein Beispiel für CentOS7:
Zuerst wird dafür ein Pool, eine Job Definition als Vorlage ein FileSet und dann noch en Zeitplan angelegt:
conf.d/storage.conf
# [...]
# basejobs pool
Pool
{
Name = file01-base
Pool Type = Backup
Recycle = yes
AutoPrune = yes
Volume Retention = 1 month
Volume Use Duration = 23h
Label Format = "base-"
}conf.d/JobDefs.conf
# [...]
JobDefs
{
Name = "base"
Type = "Backup"
Level = "Base"
Schedule = "BaseJob"
Storage = "disk01"
Messages = "Standard"
Pool = "file01-base"
Priority = "9"
Allow Mixed Priority = "no"
Write Bootstrap = "/srv/backup/bareos/bootstraps/%n.bsr"
#RunAfterJob = "scp -p /srv/backup/bareos/bootstraps/%n.bsr backup@server01:/srv/backup/bareos/bootstraps/%n.bsr"
}Anmerkung: Hier wurde Priority ein Wert runter auf „9“ und Allow Mixed Priority auf „no“ gesetzt, damit die base-backups vor den normalen Backups (mit Priority=10) laufen.
conf.d/filesets.conf
# [...]
# All linux system partitons
FileSet
{
Name = linux-system
Include
{
Options
{
signature = MD5
compression = GZIP
One FS = yes
}
File = /
File = /boot
File = /usr
File = /var
File = /home
#File = /tmp
}
}Achtung: Wenn man auf dem System auf dem das base-backup gemacht wird keine eigenen Partitionen für /boot, /usr, /var, /home und /tmp hat (bzw. nur eine root Partition), muss das obige fileset angepasst werden, da ansonsten die Partitonen doppelt gesichert würden.
conf.d/schedules.conf
# [...]
# For base jobs
Schedule
{
Name = "BaseJob"
Run = Full 1st sat at 23:05
}Dann wird bei einem der zu sichernden Systeme ein spezieller base-job definiert und dann gleich ein darauf aufnauender backup Job mit dem Zusatzattribut: Base = "centos7-base" angelegt:
conf/clients/centos7-client1.conf
Client
{
Name = centos7-client1
Address = centos7-client1.example.org
FDPort = 9102
Catalog = MysqlCatalog
Password = "@@FD_PASSWORD@@"
AutoPrune = no
}
# This serves as a base-job for all other CentOS7 hosts
Job
{
Name = "centos7-base"
Client = "centos7-client1"
JobDefs = "base"
FileSet = "linux-system"
}
# Backup the local system
Job
{
Name = "centos7-client1-system"
Base = "centos7-base"
Client = "centos7-client1"
Accurate = "yes"
JobDefs = "default"
FileSet = "linux-system"
}[stextbox id=“note“ caption=“Hinweis“]Damit das funktioniert ist zwingend das Attribut: Accurate = "yes" zu setzen. [/stextbox]
Das zweite zu sichernde System referenziert dann ebenfalls auf dieses base-backup
conf/clients/centos7-client2.conf
Client
{
Name = centos7-client2
Address = centos7-client2.example.org
FDPort = 9102
Catalog = MysqlCatalog
Password = "@@FD_PASSWORD@@"
AutoPrune = no
}
# Backup the local system
Job
{
Name = "centos7-client2-system"
Base = "centos7-base"
Client = "centos7-client2"
Accurate = "yes"
JobDefs = "default"
FileSet = "linux-system"
}Danach bareos-dir neustarten und über bconsole -> run -> centos7-base den base-job ausführen.
Danach den Job für den backup client laufen lassen: bconsole -> run -> centos7-client1-system
Im Bareos-Log kann man dass dann wie folgt verifizieren:
[...]
bareos-dir JobId 48: Start Backup JobId 48, Job=centos7-client1-system.2017-03-17_11.13.08_11
[...]
bareos-dir JobId 48: Using BaseJobId(s): 46
bareos-dir JobId 48: Sending Accurate information to the FD.
[...]
centos7-client1 JobId 48: Space saved with Base jobs: 593 MB
bareos-dir JobId 48: Bareos bareos-dir 7.0.5 (28Jul14):
[...]
Base files/Used files: 40924/22880 (55.91%)
[...]
Termination: Backup OKIn diesem Fall konnte mit dem base-job 593 MB Speicher gespart werden („Space saved with Base jobs: 593 MB“).
Datenbanken
Datenbanken müssen speziell gesichert werden, da hier nicht einfach die Dateien „weg kopiert“ werden können.
Meist haben die Datenbanken Kommandozeilenprogramme um einen „dump“ der Datenabank zu erzeugen.
Hier ein Beispiel für mysql, welches dafür das Programm mysqldump hat.
Zuerst wird wie immer der Backup-Job definiert:
conf.d/clients/db-server1.conf
Client
{
Name = db-server1
Address = db-server1.example.org
FDPort = 9102
Catalog = MysqlCatalog
Password = "@@FD_PASSWORD@@"
AutoPrune = no
}
# All databases ONLINE backup with extended db/table checks
Job
{
Name = "db-server1-database"
Client = "db-server1"
JobDefs = "database"
FileSet = "db-server1-database"
# Backup of all mysql databases
ClientRunBeforeJob = "/usr/local/libexec/bareos/db-backup.sh"
ClientRunAfterJob = "/bin/rm -f /var/spool/backup/mysql/mysqldump-full.sql"
}Nun noch eine spezielle Job-Definition in conf.d/JobDefs.conf anlegen:
# [...]
JobDefs
{
Name = "database"
Type = "Backup"
Level = "Full"
Schedule = "WeeklyCycle"
Storage = "disk01"
Messages = "Standard"
Pool = "file01-database"
Priority = "10"
Allow Mixed Priority = "yes"
Write Bootstrap = "/srv/backup/bareos/bootstraps/%n.bsr"
#RunAfterJob = "scp -p /srv/backup/bareos/bootstraps/%n.bsr backup@server2:/srv/backup/bareos/bootstraps/%n.bsr"
}[stextbox id=“tip“ caption=“Ein eigener Pool für Datenbank-Backups“]
Da Datenbank-Backups aus einem Dumpfile bestehen, welches ständig ändert enspricht so ein Backup immer einer „Voll“-Sicherung; Inkrementelle oder Differentielle Sicherungen sind hier nicht möglich.
Deshalb möchte man vieleicht unterschiedliche Vorhaltezeiten definieren als für nomrale Dateisicherungen. Hier bietet sich das erstellen eines eigenen Pools und FileSet an:
conf.d/storage.conf
# [...]
# Separate Pool for database backups
# DB pool (limited retention)
Pool
{
Name = file01-database
Pool Type = Backup
Recycle = yes
AutoPrune = yes
Volume Retention = 5 days
Volume Use Duration = 23h
Label Format = "db-"
} |
conf.d/filesets.conf
# [...]
# Separate FileSet for database backups
FileSet
{
Name = "db-server1-database"
Include
{
Options
{
signature = MD5
OneFS = no
}
File = /var/spool/backup/mysql
}
} |
[/stextbox]
Auf dem Datenabnk-Server (db-server1) wird nun das Backup- und Script-Verzeichnis erstellt:
mkdir -pv /var/spool/backup/mysql/ /usr/local/libexec/bareos/Und das Script welchesen den Datenbank-Dump erstellt:
/usr/local/libexec/bareos/db-backup.sh
#!/bin/bash
mysqldump --all-databases --opt --complete-insert --compress --events --routines --triggers > /var/spool/backup/mysql/mysqldump-full.sqlchmod -v +x /usr/local/libexec/bareos/db-backup.shDamit wird nun:
- Vor dem Backup mit mysqldump ein Datenbank dump in /var/spool/backup/mysql/ abgelegt
- Beim Backup der Inhalt von /var/spool/backup/mysql/ gesichert
- Nach dem Backup der Inhalt von /var/spool/backup/mysql/ wieder gelöscht
ESX
Konfiguration
Um Backups von ESX-Servern anzulegen muss auch erst das externe Tool vicfg-cfgbackup verwendet werden.
Um dieses Tool kann ein kleines wrapper Script erstellt werden; dieses kann von jedem Server aus laufen, auf dem die vSphere CLI tools installiert sind.
In diesem Bespiel läuft es auf dem backup-server, welcher das Backup mittels lokal installierter vCLI aufruft.
In der Variablen ESX_SERVERS können ausserdem gleich mehrere ESX-Server gesichert werden.
Und da ESX immer dieselbe Version des Backups braucht wie gerade ausgeführt wird, schreiben wir dieses auch noch in in den Dateinamen.
Damit das funktioniert, muss man aber erst ein SSH private/public keypar erzeugen und dieses im ESX einfügen:
Auf dem Server auf dem das Script ausgeführt wird:
ssh-keygen -t rsa -b 2048Nun nimmt man den Inhalt aus dem entstandenen .ssh/id_rsa.pub und schribt dieses mit dem prefix command="uname -r" bei jedem ESX in die Datei: /etc/ssh/keys-root/authorized_keys:
command="uname -r" ssh-rsa AAABBBCCCDas command= davor bewirkt, dass nur dieses Kommando ausgeführt werden darf; denn es wäre wirklich unklug, wenn sich der Benutzer des Backup-Servers als root in den ESX-Server einloggen könnte.
Dazu noch spezielles Verzeichnis für bareos Scripte angelegt wird:
mkdir -pv /usr/local/libexec/bareos/Nun das Script dazu, welches zwei Paramater besitzt: „pre“ und „cleanup“:
/usr/local/libexec/bareos/esx-backup.sh
# Variables
DIR_BACKUP="/var/spool/backup/esx"
APP_SSH="/usr/bin/ssh -o StrictHostKeyChecking=no -i /home/vmware/.ssh/id_rsa"
APP_BACKUP="sudo -u vmware /usr/local/bin/vicfg-cfgbackup"
ESX_SERVERS=( "esx1.example.com" "esx2.example.com" )
RC=0
case "$1" in
pre)
# Create the backups
echo "BEGIN ESX config backup"
mkdir -p $DIR_BACKUP; RC=$(($RC+$?))
for esx_server in ${ESX_SERVERS[*]}; do
# Get version
esx_version=$($APP_SSH root@${esx_server} "uname -r")
$APP_BACKUP --server $esx_server -s ${DIR_BACKUP}/${esx_server}-${esx_version}.tgz; RC=$(($RC+$?))
done
echo "END ESX config backup"
echo "Finished with rc=$RC"
exit $RC
;;
cleanup)
# Cleanup
rm -f $DIR_BACKUP/*.tgz
;;
*)
echo $"Usage: $0 {pre|cleanup}"
exit 1
esacDann das Script noch ausführbar machen:
chmod -v 755 /usr/local/libexec/bareos/esx-backup.shUnd ein Job dafür anlegen:
conf.d/clients/backup-server.conf
# [...]
# Backup files on external hosts, which do not have bareos-fd running
# and therefore are running from this host
# ESX backups
Job
{
Name = "ADMIN-extra-backups"
Client = "backup-server"
JobDefs = "default"
Level = Full
FileSet = "linux-local-backup"
RunBeforeJob = "/usr/local/libexec/bareos/esx-backup.sh pre"
RunAfterJob = "/usr/local/libexec/bareos/esx-backup.sh cleanup"
}Genau so kann man nur auch für so ziemlich alles verfahren welches irgendwie backup Dateien produzieren kann, wie z.B. pfsense.
Virtuelle Maschinen (VMs)
Mittels dem tool ghettoVCB, welches auf ESX Maschinen erlaubt ein Backups laufender VMs zu machen (ähnlich wie das z.B. das Kommerzielle Produkt veeam macht).
Dies gibt es mittlerweile auch als VIB, oder offline bundle, so dass man es „permanent“ auf einem ESX-Server installieren kann.
Und in Kombination mit bareos lassen sich so eifach auch scheduled backups machen. Im nachfolgenden wird die Konfiguration erklärt.
Da auf dem esx-server kein bareos-client installiert werden kann, muss das Backup von einem anderen client per SSH angestossen- und dann die Daten von bareos auch per SSH-Pipe gelesen werden.
Im folgenden Beispiel wird das auf dem backup-server gemacht, worauf ggf. noch ein SSH public/private keypair erstellt werden muss:
[bareos@backup-server ~]$ ssh-keygen -t rsa -b 2048Nun nimmt man den Inhalt von ~/.ssh/id_rsa.pub und fügt diesen auf dem esx-server in: /etc/ssh/keys-root/authorized_keys ein.
Somit müsste man sich vom backup-server nun ohne passwort zum esx-server verbinden können:
[bareos@backup-server ~]$ ssh -i ~/.ssh/id_rsa root@esx-serverNun installiert man auf den ESX-Servern ghettoVCB:
esxcli software vib install -v /vghetto-ghettoVCB.vib -fDanach werden in: /etc/ghettovcb/ghettoVCB.conf die folgeden Paramater angepasst:
VM_BACKUP_VOLUME=/vmfs/volumes/datastore1/backup
VM_BACKUP_ROTATION_COUNT=1Der Rest kann beim standard belassen werden.
Danach wird in die Datei: /etc/ghettovcb/vms_to_backup noch die Liste der VMs, welche gesichert werden sollen geschrieben.
Nun wird in der bareos Konfiguration ein neues FileSet angelegt:
FileSet
{
Name = "vm-backup-esx"
Include
{
Options
{
signature = MD5
OneFS = no
}
Plugin = "bpipe:/var/spool/backup/vms.tar:ssh -i /srv/backup/bareos/.ssh/id_rsa -o StrictHostKeyChecking=no root@esx-server /bin/tar -c /vmfs/volumes/datastore1/backup:/bin/tar -C /srv/backup/bareos/devices/bareos-restores -xvf -"
}
}Anstelle der üblichen File-Anweisung wird hier das Plugin „bpipe“ aufgerufen. Damit kann man eine TAR-Datei der Backups erstellen und direkt via SSH im Backup ablegen, anstelle dieses zuvor noch temporär zwischenspeichern zu müssen.
Der Pfad nach bpipe:/ ist dabei ein „Pseudo-Pfad“ wie er danach im Backup heisst, da es ja kein echter Pfad gab. Dieser kann frei gewählt werden, sofern es sich nicht um einen realen Pfad handelt, der irgendwo im Backup noch gesichert wird.
Mittels dem SSH-Paramater -i wird der ssh private key angegeben, danach folgt das tatsächliche Verzeichnis mit den Backups und einen Pfad auf welchen die Datei bei einem restore auf dem client abgelegt würde.
Auch hier empfielhlt es sich wieder einen eigenen Storage-Pool zu machen, da die Backup-Dateien mit den VMs natürlich sehr gross werden können:
Pool
{
Name = file01-vm
Pool Type = Backup
Recycle = yes
AutoPrune = yes
Volume Retention = 2 days
Volume Use Duration = 23h
Label Format = "vm-"
}Die retention wurde hier zusätzliche auf 2 Tage herunter gesetzt.
Nun noch eine neue Job-Definition:
JobDefs
{
Name = "vm"
Type = Backup
Level = Full
Schedule = "WeeklyCycle"
Storage = disk01
Messages = Standard
Accurate = yes
Pool = file01-vm
Priority = 10
Allow Mixed Priority = yes
Write Bootstrap = "/srv/backup/bareos/bootstraps/%n.bsr"
RunAfterJob = "scp -p /srv/backup/bareos/bootstraps/%n.bsr backup@server1:/srv/backup/bareos/bootstraps/%n.bsr"
}und schlussendlich der Job:
Job
{
Name = "vm-backups"
Client = "backup-server"
JobDefs = "vm"
FileSet = "vm-backup-esx"
ClientRunBeforeJob = "ssh -i /srv/backup/bareos/.ssh/id_rsa -o StrictHostKeyChecking=no root@esx-server /opt/ghettovcb/bin/ghettoVCB.sh -g /etc/ghettovcb/ghettoVCB.conf -f /etc/ghettovcb/vms_to_backup"
ClientRunAfterJob = "ssh -i /srv/backup/bareos/.ssh/id_rsa -o StrictHostKeyChecking=no root@esx-server rm -rf /vmfs/volumes/local-raid1-ds01/BACKUP/ghettovcb/*"
}Weitere Informationen zu dem Thema findet sich im bacula Beitrag: VMware Virtual Machines Back up With Bacula and GhettoVCB.
LVM snapshots um datenkonsistenz zu erhalten
Verändert ein Prozess, z.B. eine Web-Applikation ständig Dateien auf dem Server würde man nie ein konsistentes Backup haben.
Man könnte zwar die Applikation während dem der Sicherung stoppen, doch hätte man dann eine lange Zeit in welcher der Service nicht verfügbar wäre.
Liegen die Dateien auf einer LVM Partition, muss man die Applikation hingegen nur kurz beenden um ein snapshot zu erzeugen; danach kann die Applikation wieder gestartet- und in aller Ruhe die Dateien gesichert werden.
Hier ein Beispiel für ein RunScript für den apache Webserver, welches dazu gleich noch mySQL Datenbank Backups anfertigt.
Eingebunden wird es wie in den vorherigen Beispielen.
/usr/local/libexec/bareos/consistent-web-backup.sh
#!/bin/bash
# Variables
RC=0
ERRORS=0
DIR_WWW="/srv/www"
DIR_BACKUP_MYSQL="/var/spool/backup/mysql"
DIR_BACKUP_WWW="/var/spool/backup/www"
VG_BACKUP_WWW="rootvg"
LV_BACKUP_WWW="www"
MYSQL_USER="backup"
MYSQL_PASS="secret"
APP_SUDO="/usr/bin/sudo"
APP_MYSQL="/usr/bin/mysql -u$MYSQL_USER -p$MYSQL_PASS"
APP_MYSQLDUMP="/usr/bin/mysqldump -u$MYSQL_USER -p$MYSQL_PASS"
APP_MYSQLCHECK="/usr/bin/mysqlcheck -u$MYSQL_USER -p$MYSQL_PASS"
APP_GZIP="/bin/gzip"
APP_LVCREATE="$APP_SUDO /sbin/lvcreate"
APP_LVREMOVE="$APP_SUDO /sbin/lvremove"
APP_MOUNT="$APP_SUDO /bin/mount"
APP_UMOUNT="$APP_SUDO /bin/umount"
MOUNTPOINT="/bin/mountpoint"
APP_RM="$APP_SUDO /bin/rm"
MAX_FS_LOCK_ATTEMPTS=10
# Functions
snapshot_remove ()
{
if [[ -e "/dev/$VG_BACKUP_WWW/www_snap" ]]; then
$APP_LVREMOVE -f $VG_BACKUP_WWW/www_snap
fi
}
case "$1" in
pre)
# Inform logged in users
wall "Locking filesystem $DIR_WWW in order to to backups. If you are accessing this directory change it or log out NOW"
# Stop wevserver and wait for shutdown
echo "Stopping httpd..."
systemctl stop httpd
FS_LOCK_ATTEMPTS=0
while [[ -n "$(/usr/bin/pgrep -f 'httpd')" || -n "$(/usr/bin/pgrep -f 'php')" || -n "$($APP_SUDO /sbin/fuser -m $DIR_WWW)" ]]
do
if [ "$FS_LOCK_ATTEMPTS" -lt "$MAX_FS_LOCK_ATTEMPTS" ]; then
echo "proc HTTP: $(/usr/bin/pgrep -f 'httpd') / PHP: $(/usr/bin/pgrep -f 'php') still running and/or accessing the filesystem ($($APP_SUDO /sbin/fuser -m $DIR_WWW))... (attempt: $FS_LOCK_ATTEMPTS / $MAX_FS_LOCK_ATTEMPTS)"
sleep 3
((FS_LOCK_ATTEMPTS++))
else
echo "Max attempts to lock the filesystem exeeded, giving up."
systemctl start httpd
ERRORS=$((ERRORS+1))
exit 1
fi
done
echo "httpd stopped and no processes accessing the filesystem: $DIR_WWW."
# Dump mysql DBs
echo "Dumping mysql databases..."
$APP_MYSQL -s -r -e 'show databases' | grep -Ev 'Database|information_schema' | while read dbname; do $APP_MYSQLDUMP --opt --complete-insert --events --routines --triggers --databases "$dbname" |$APP_GZIP > "$DIR_BACKUP_MYSQL/$dbname".sql.gz; done
RC=$?
if [ $RC != 0 ]; then ERRORS=$((ERRORS+1)); fi
echo "mysql databases dumped. (exitcode: $RC)"
# Create and mount filesystem snapshot
echo "Creating and mounting filesystem snapshot..."
mkdir -p $DIR_BACKUP_WWW
$APP_LVCREATE -l 5%ORIGIN -s -n www_snap $VG_BACKUP_WWW/$LV_BACKUP_WWW
$APP_MOUNT -o ro /dev/$VG_BACKUP_WWW/www_snap $DIR_BACKUP_WWW
$MOUNTPOINT -q "$DIR_BACKUP_WWW"
if [ $? -eq 0 ]; then
echo "filesystem snapshot created and mounted."
else
echo "ERROR: Mount of $DIR_BACKUP_WWW failed, removing snapshot"
snapshot_remove
ERRORS=$((ERRORS+1))
fi
# Start webserver again
echo "Starting httpd..."
systemctl start httpd
if [ "$ERRORS" -eq 0 ]; then
echo "httpd started. Ready for backup."
else
echo "Errors during pre-script. (errors: $ERRORS)"
exit "$ERRORS"
fi
;;
cleanup)
# Cleanup
$APP_UMOUNT /var/spool/backup/www
snapshot_remove
$APP_RM -f /var/spool/backup/mysql/*.gz
;;
*)
echo $"Usage: $0 {pre|cleanup}"
exit 1
esacVorsichtsmassnahmen
Exit-Code bei RunScripts
Erstellt man RunScripts für bareos Jobs, muss unbedingt darauf geschaut werden, dass der Exit-/Return code von jedem Programm welches darin aufgerufen wird, abgefangen- und das Script im Fehlerfall auch mit einem Code >0 beendet wird.
Denn wenn das Script ohne exit Anweisung beendet wird, gibt es immer „0“ (=OK) zurück. Bareos würde in einem solchen Fall denken, es ist alles gut gelaufen und den Job als erfolgreich erledigt markieren!
Das Folgende Besipiel verdeutlicht dies:
Script:
backup-script.sh
createBackup "wichtige Daten"Aufruf:
./backup-script.sh
Error: cannot save "wichtige Daten"Aus Sicht von Bareos wäre jedoch alles ok, da das Script mit dem Ok-Code 0 beendet wurde.
Besser so:
Script:
backup-script.sh
createBackup "wichtige Daten"
RC=$?
exit $RCSchlägt jetzt das Script fehl, so wird die Variable RC nicht 0 sein und diese am Schluss mit exit dem Script übergeben.
In einem solchen Fall würde Bareos das Backup als „Nicht erfolgreich“ markieren und entsprechend raportieren.
[stextbox id=“note“ caption=“Anmerkung zu exit codes“]
Bei der Fehlerbehandlung ist zu beachten, dass nicht jeder Exit-Code, welcher grösser als 0 ist, ein Fehler bedeuten muss.
Das oft verwendete Programm rsync hat z.B. auch „gute“ exit codes, welche im Script ausgefiltert werden sollten.
Hier ein Beispiel für rsync:
rsync /local/directory/ server:/remote/directory/ RC=$? if [ $RC == 24 ]; then RC=0; else RC=$RC; fi echo "Transfer sync ended with code: $RC" exit $RC |
[/stextbox]
set -e for the rescue
Noch besser ist es, wenn man bei jedem Backup Script zuoberst die Optionen set -e -o pipefail mitgibt, z.B.
#!/bin/bash
set -eo pipefail
# Beginn des Backup ScriptsDann wird das Script nämlich automatisch abgebrochen, wenn es irgendwo einen Fehler gibt, was dann auch in Backup Job zu einem Fehlerstatus führt.
Quellen
- Installing Webmin, Bareos 7 and Bareos-Web on CentOS 7
- bareos.org: Can I migrate from Bacula to Bareos?
- Bareos und Notebooks: Erklärt wie man Notebooks mit Bareos sichern kann
Hallo, supper Beitrag.
Ich selbst nutze auch Bacula für meine Server.
Was die Vorhaltezeit angeht „2 Monate“ wäre meine Frage, Wie sieht die Volume Retention der Catalog Datenbank aus?
Was ich nicht ganz verstehe, wie richte ich es ein, dass ich das Vollbackup 3 Jahre aufheben bzw. wieder zurückspielen kann.
Müsste ich die Volume Retention des Catalogs auf 3 Years setzen oder kann ich am Ende des Jahres die Vollsicherung exportieren.?
Wenn es um Jahressicherungen geht, habe ich alles im Griff, aber wenn dies länger sein sollen, dann komme ich etwas ins schleudern.
Noch etwas zum Thema Vollsicherungen.
Ich benötige für einen restore immer eine Vollsicherung.
Wenn ich nun 1ne Vollsicherung im Monat mache, und bei dieser geht etwas schief, dann kann ich eigentlich zurückliegend keine Rücksicherung mehr durchführen „für den letzen Mionat“
Gerade in der heutigen Zeit wo doch Hardware nicht wirklich teuer ist, würde ich die Vollsicherung jede Woche vornehmen.
Ich sehe da ein Zeitproblemchen.
Ansonsten Supper Beitrag! Vielen Dank.
Vielleicht könnte ich Dir noch ein paar Fragen stellen, meine Mail hast du ja jetzt.
Herzliche Grüsse
Grundsätzlich hat die Volume Retention der Catalog Datentank keinen Einfluss wie lange die Backups behalten- und zurück gespielt werden können.
Bei der Volume Retention der Catalog Datenbank handelt es sich nur um die Sicherung der Katalog Datenbank selbst und diese ist nur dann nötig, wenn der Backup-Server selbst ausfällt. Deshalb reicht es da oft, die Retention der Katalog-Sicherungen auf einen Monat zu setzten, was heisst eine tägliche Sicherung, welche jeweils einen Monat behalten wird und zusätzlich noch einen nächtlichen Dump der Datenbank auf einen externen Server.
Die Daten im Katalog selbst, also in der laufenden Datenbank, bleiben so lange bestehen, wie die Retention der Sicherungs Volumes ist. – Du brauchst hier lediglich aufzupassen, dass die File Retention und Job Retention nicht gesetzt ist, oder auf jeden Fall höher als die Volume Retention. Ansonsten würde der Job zu früh aus der Katalog-Datenbank gelöscht.
Wenn du einen bestimmten Backup Job 3 Jahre vorhalten willst, konfigurierst du einfach einen separaten Volume Pool dafür und setzt dann die Volume Retention auf 3 Jahre (3 years).
Du kannst natürlich auch die Dateien der Vollsicherung jeweils nach einem Jahr, zusammen mit der/den bootstrap Datei(en) auslagern. Sie verschwinden zwar dann je nachdem aus der Datenbank, sind jedoch zusammen mit den Bootstrap Dateien wieder relativ einfach herstellbar.
Zur zweiten Frage: Falls eine Vollsicherung schief geht (das heisst aus irgendeinem Grund abgebrochen wird), versucht bacula bei der nächsten Sicherung erneut eine Vollsicherung. Es wird also z.B. keine inkrementelle Sicherung auf eine „defekte“ Vollsicherung gemacht.
Und auch im dümmsten Fall hat man dann immer noch die (hoffentlich intakte) Sicherung des Vor-Monats, da erst ab dem dritten Monat die Sicherung des ersten Monats überschrieben wird.
Bei der Vollsicherung jede Woche braucht man halt je nachdem wie viel man sichert schon sehr viel Speicherplatz, was aufgrund oben erwähnten Gründen eigentlich unnötig ist.